In a nutshell: Remove from ViewControllers all tasks which are not view-related.
Quick Links:
Architecture Diagram PDF
Example Project
Problems with ViewControllers in MVC
The View Controller is typically the highest level of organization in the iOS standard MVC app. This tends to make them accumulate a wide variety of functionality that causes them to grow in both size and complexity over the course of a project’s development. Here are the basic issues I have with the role of view controllers in the “standard” iOS MVC pattern:
- Handle too many tasks:
- View hierarchy management
- API Interaction
- Data persistence
- Intra-Controller data flow
- Need to have knowledge of other ViewControllers to pass state along.
- Difficult to test business logic tied to the view structure.
Guiding Principles of Coordinated MVC
Tasks, not Screens
The architecture adds a level of organization above the View Controller called the Coordinator layer. The Coordinator objects break the user flow of your app into discrete tasks that can be performed in an arbitrary order. Example tasks for a simple shopping app might be: Login, Create Account, Browse Content, Checkout, and Help.
Each Coordinator manages the user flow through a single task. It is important to note that there is not a unique relationship between Coordinators and the screens they manage; multiple Coordinators can call upon the same screen as part of their flow. We want a Coordinator to completely define a task from beginning to completion, only changing to a different Coordinator when the task is complete or the user takes action to switch tasks in mid-flow.
Rationalle: When View Controllers must be aware of their role within a larger task, they tend to become specialized for that role and tightly coupled to it. Then, when the same view controller is needed elsewhere in the app, the developer is faced with the task of either putting branching logic all over the class to handle the different use cases or duplicating the class and making minor changes to it for each use case.
When combined with Model Isolation and Mindful State Mutation, having the control flow of the app determined at a higher level than the view controller solves this scenario, allowing the view controller to be repurposed more easily.
Model Isolation
View Controllers must define all of their data requirements in the form of a DataSource protocol. Every view controller will have a var dataSource: DataSource? property that will be its sole source of external information. Essentially, this is the same as a View Model in the MVVM pattern.
Rationale: When View Controllers start reaching out directly to the Model or service-layer objects (API clients, persistence stacks, etc.) they begin to couple the model tightly to their views, making testing increasingly difficult.
Mindful State Mutation
View Controllers shall define all of their external state mutations in the form of a Delegate protocol. Every view controller will have a var delegate: Delegate? property that will be the only object that the View Controller reaches out to in order to mutate external state. That is to say, the View Controller can take whatever actions are necessary to ensure proper view consistency, but when there is a need to change to a new screen or take some other action that takes place “outside” itself, it invokes a method on its delegate.
Rationale: In the traditional MVC architecture, View Controllers become tightly coupled to each other, either by instantiating their successor view controller and pushing it onto a Nav Controller, or by invoking a storyboard segue and then passing model and state information along in prepareForSegue(). This coupling makes it much more difficult to test that the user flow of your app is working as expected, particularly in situations with a lot of branching logic.
The Architecture in Depth
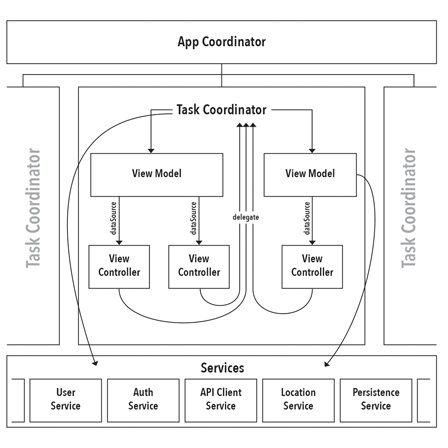
Download PDF Version
Task
A global enum that contains a case for every possible user flow within the app. Each task should have its own TaskCoordinator.
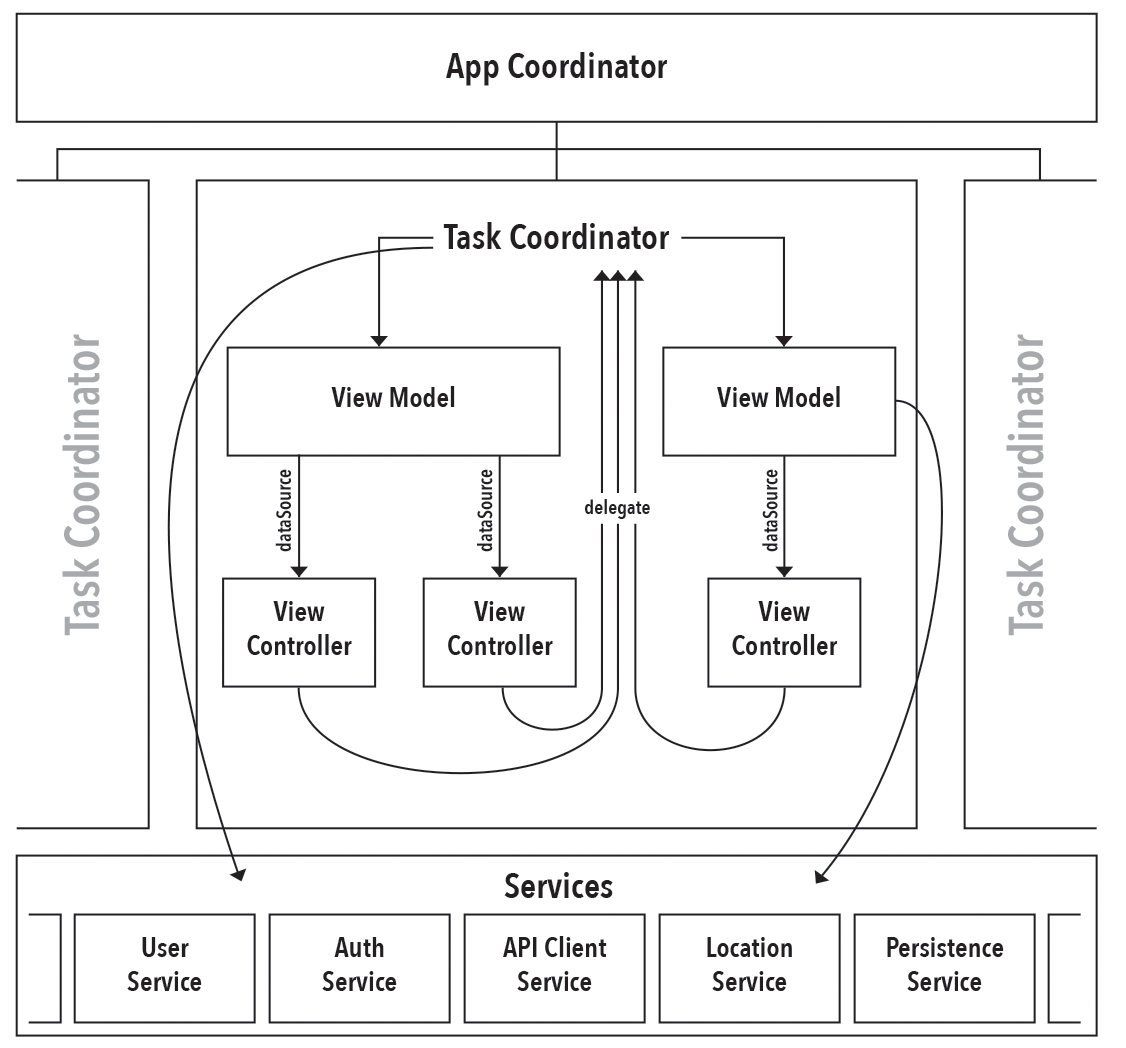
App Coordinator
The ultimate source of truth about what state the app should be in. It manages the transitions between the TaskCoordinator objects. It decides which Task should be started on app launch (useful when deciding whether to present a login screen, or take the user straight to content). The AppCoordinator decides what to do when a Task completes (in the form of a delegate callback from the currently active TaskCoordinator).
The AppCoordinator holds a reference to the root view controller of the app and uses it to parent the various TaskCoordinator view controllers. If not root view controller is specified, the AppCoordinator assumes it is being tested and does not attempt to perform view parenting.
The AppCoordinatorcreates and retains the service layer objects, using dependency injection to pass them to the TaskCoordinators which then inject them into the ViewModels.
Task Coordinator
Manages the user flow for a single Task through an arbitrary number of screens. It has no knowledge of any other TaskCoordinator and interacts with the AppCoordinator via a simple protocol that includes methods for completing its Task or notifying the AppCoordinator that a different Task should be switched to.
TaskCoordinators create and manage the ViewModel objects, assigning them as appropriate to the dataSource of the varous View Controllers that it manages.
Service Layer
Objects in the service layer encapsulate business logic that should be persisted and shared between objects. Some examples might be a UserAuthenticationService that tracks the global auth state for the current user or an APIClient that encapsulates the process of requesting data from a server.
Service layer objects should never be accessed directly by View Controllers! Only ViewModel and Coordinator objects are permitted to access services. If a View Controller needs information from a service, it should declare the requirement in its DataSource protocol and allow the ViewModel to fetch it.
Avoid giving in to the siren call of making your service layer objects as singletons. Doing so will make testing your Coordinator and ViewModel objects more difficult, because you will not be able to substitute mock services that return a well-defined result.
If you want to do data/API response mocking—say because the API your app relies on won’t be finished for another couple of weeks—these objects are where it should occur. You can build finished business logic into your ViewModel and Coordinator objects that doesn’t need to change at all once you stop mocking data and connect to a live API.
View Model
ViewModel objects are created and owned by TaskCoordinators. They should receive references to the service layer objects they require in their constructors (dependency injection). A single ViewModel may act as the DataSource for multiple View Controllers, if sharing state between those controllers is advantageous.
ViewModels should only send data down to the View Controller, and should not be the recipient of user actions. The TaskCoordinator that owns the ViewModel and is acting as the View Controller’s delegate will mutate the ViewModel with state changes resulting from user actions.
Putting it into Practice
I have created a simple “Weather App” example project that shows the architecture in action:
Example Project
Here’s how to follow flow:
- In the
AppDelegate you can see the AppCoordinator being instantiated and handed the root view controller.
- In the
AppCoordinator‘s init method, observe how it checks to see if the user has “logged in”.
- If the user is not logged in, the user is directed to the Login task to complete logging in.
- If the user is logged in, then they are taken directly to the Forecast task.
- When tasks have completed their objective, they call their delegate
taskCooordinator(finished:) method. This triggers the AppCoordinator to determine what the next task is. In a fully-fledged app, there could be a considerable amount of state inspection as part of this process.
Quick Rules for Conformance
- No view controller should access information except from its
dataSource (View Model).
- No view controller should attempt to mutate state outside of itself except through its
delegate (usually a TaskCoordinator).
- No view controller should have knowledge of any other view controller save those which it directly parents (embed segue or custom containment).
- View Controllers should never access the Service layer directly; always mediate access through the
delegate and dataSource.
- A view controller may be used by any number of
TaskCoordinator objects, so long as they are able to fulfill its data and delegation needs.
Thanks
A big thank you to Soroush Khanlou and Chris Dzombak and their fantastic Fatal Error podcast for giving me inspiration to create this.